

InvokeAI是一个前沿的人工智能技术解决方案提供者,致力于通过其高级AI模型推动各行各业的智能化转型。该平台集成了最新的机器学习算法,帮助开发者和企业打造智能应用程序,从而提高工作效率,优化用户体验。

平台涵盖了自然语言处理、计算机视觉、推荐系统等多个AI领域的服务。InvokeAI可以轻松整合到现有的系统中,通过API和开发工具包的形式,使得功能的扩展和定制变得非常灵活。让用户无论在文本解析、图像识别还是数据分析等方面都能获得强有力的支持。
每个InvokeAI服务背后都有着强大的算力支撑,确保了处理速度和精度。此外,平台的智能分析能力强大,能够提供深入的见解和预测,为决策者带来宝贵的数据支持。InvokeAI继续在人工智能领域中不断探索,旨在通过其高效可靠的AI服务推动技术进步,助力企业释放潜力,开启智能化新纪元。
WebUI 功能的快速引导演练#
虽然大多数 WebUI 的功能都很直观,但这里有一个有关其各个组件的引导演练。
启动 WebUI #
要运行 InvokeAI Web 服务器,请启动 invoke.sh / invoke.bat 脚本并选择选项 (1)。或者,在 InvokeAI 环境处于活动状态时,运行 invokeai-web :
invokeai-web
然后,您可以通过将 Web 浏览器指向 http://localhost:9090 连接到服务器。要从 LAN 上的另一台计算机访问服务器,您可以使用 --host 参数以及运行该服务器的主机的 IP 地址或通配符 0.0.0.0
invoke.sh --host 0.0.0.0
或者
invokeai-web --host 0.0.0.0
InvokeAI Web 界面 #
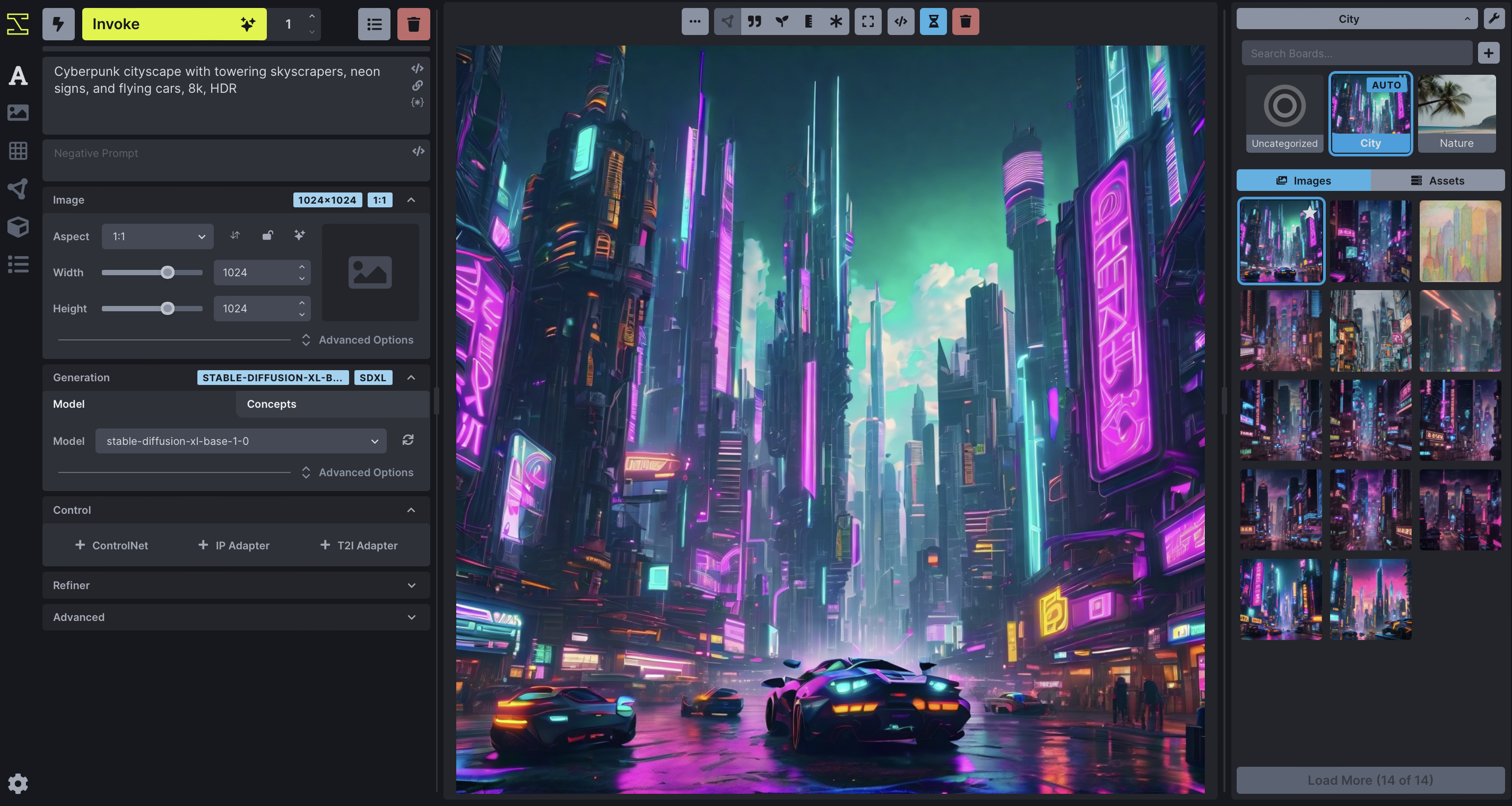
上面的屏幕截图显示了 WebUI 的“文本到图像”选项卡。主要分为三个部分:
-
左侧的控制面板,包含文本到图像生成的各种设置。最重要的部分是用于输入肯定文本提示的文本字段(当前显示
fantasy painting, horned demon),其正下方的另一个文本字段用于输入可选的否定文本提示(要排除的概念),以及用于开始的“调用”按钮图像渲染过程。 -
中间的当前图像部分,显示您当前正在处理的图像的大格式版本。顶部的一系列按钮可让您以各种方式修改和操作图像。
-
左侧的图库部分包含您生成的图像的历史记录。这些图像被读取并写入
INVOKEAIROOT/invokeai.yaml初始化文件中指定的目录,通常是INVOKEAIROOT中名为outputs的目录。
除了这三个元素之外,右上角还有一系列用于更改全局设置、报告错误和更改主题的图标。
控制面板左侧还有一系列图标(请参见下面屏幕截图中的突出显示区域),可在一系列选项卡中进行选择以执行不同类型的操作。
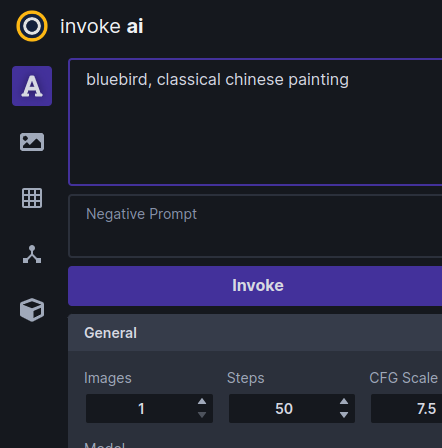
从上到下,这些是:
- 文本到图像 - 从文本生成图像
- 图像到图像 - 从上传的起始图像(绘图或照片)生成新图像,并通过文本提示进行修改
- 统一画布 - 交互式地组合多个图像,通过修复来扩展它们,通过修复来修改图像的内部部分,擦除起始图像的部分,并让人工智能根据文本提示填充擦除的区域。
- 节点编辑器 -(实验性)此面板允许您创建常见操作的管道并将它们组合到工作流程中。
- 模型管理器 - 此面板允许您使用 URL、本地路径或 HuggingFace 扩散器 repo_ids 导入和配置新模型。
演练#
以下演练将练习大部分(但不是全部)WebUI 的功能集。
文本到图像#
-
使用启动器选项 [1] 启动 WebUI,并通过访问
http://localhost:9090使用浏览器连接到它。如果浏览器和服务器在 LAN 上的不同计算机上运行,请将选项--host 0.0.0.0添加到invoke.sh启动命令行,并使用其 IP 地址连接到托管 Web 服务器的计算机,或者域名。 -
如果一切顺利,WebUI 应该会出现,您会在右上角看到一个表示
connected的绿点。
基本 #
- 通过在左上角的大提示字段中输入 bluebird 来生成图像,然后单击“调用”按钮或按返回按钮。短暂等待后,您将在图像面板中看到蓝知更鸟的大图像,并在右侧图库中看到新的缩略图。
- 如果您需要更多屏幕空间,可以通过键入 g 热键关闭图库。您可以稍后通过单击图库位置中显示的图像图标将其重新打开。单击图像库上方的键盘图标可以找到热键列表。
-
通过调整“调用”按钮下方的“图像”计数器来增加请求的图像数量,从而生成一堆蓝鸟图像。每个生成后,它将被添加到图库中。您可以通过单击图库缩略图来切换活动图像。
如果您想查看图像生成进度,请单击主图像区域上方的沙漏图标。随着生成的进展,您将看到最终图像的越来越详细的版本。
-
尝试使用不同的设置,包括更改主模型、图像宽度和高度、调度程序、步骤和 CFG 比例。
该模型更改了主模型。现在有数以千计的自定义模型可供使用,它们可以生成各种图像风格和主题。虽然 InvokeAI 附带了一些入门模型,但可以轻松地将新模型导入到应用程序中。有关更多详细信息,请参阅安装模型。
图像宽度和高度符合您的预期。但请注意,较大的图像会消耗更多的 VRAM 内存,并且生成时间也会更长。
-
调度程序控制 AI 如何选择要显示的图像。一些采样器比其他采样器更具“创造性”,并且会产生更广泛的变化(请参见下一节)。一些采样器比其他采样器运行得更快。
-
步骤控制 AI 将采取的噪声/去噪/采样步骤数。该值越高,图像越精细,但生成图像所需的时间越长。一种典型的策略是使用较少的步骤生成图像,以便选择一个进行进一步处理,然后使用较多的步骤重新生成它。
-
CFG Scale 控制 AI 尝试将生成的图像与输入提示进行匹配的程度。您可以根据需要设置任意高或低的值,但通常大于 20 的值不会有太大改善,而小于 5 的值会产生意外的图像。 Steps、CFG Scale 和 Scheduler 之间存在复杂的交互,因此请尝试找出适合您的方法。
-
Seed 控制 InvokeAI 随机数生成器返回的一系列值。每个独特的种子值都会生成不同的图像。要重新生成以前的图像,只需使用原始图像的种子值即可。每次生成图像时,“种子”字段右侧的滑块将更改种子。
-
要重新生成以前生成的图像,请选择所需的图像,然后单击图像顶部的星号(“*”)按钮。这会将文本提示和其他原始设置加载到控制面板中。如果您随后按“调用”,它将准确地重新生成图像。您还可以有选择地修改提示或其他设置来调整图像。
-
或者,您可以单击“发芽植物图标”仅加载图像的种子,并保持其他设置不变,或者单击引号图标仅加载正面和负面提示。
-
要重新生成由另一个 SD 包生成的稳定扩散图像,您需要知道其文本提示及其种子。将提示复制粘贴到提示框中,取消设置控制面板中的随机种子控件,然后将所需的种子复制粘贴到其文本字段中。当你调用时,你会得到与原始图像类似的东西。除非您还为原始采样器、CFG、步长和尺寸设置正确的值,否则它不会准确,但它(通常)会很接近。
-
要保存图像,右键单击它会弹出一个菜单,您可以在其中下载图像、将其保存到指定的图像库、并将其复制到剪贴板等。
升级#
“放大”是在保持清晰度的同时增加图像尺寸的过程。 InvokeAI 使用名为“ESRGAN”的外部库来执行此操作。要调用放大,只需选择图像并按其上方的“扩展箭头”按钮即可。您可以选择2X和4X放大,并调整放大强度,这与面部重建中的含义大致相同。尝试在之前生成的图像之一上运行此命令。
图像到图像#
InvokeAI 可让您获取现有图像并将其用作新创作的基础。您可以使用任何类型的图像,包括照片、扫描草图或数字绘图,只要它是 PNG 或 JPEG 格式即可。
在本教程中,我们将使用名为 Lincoln-and-Parrot-512.png 的文件。
-
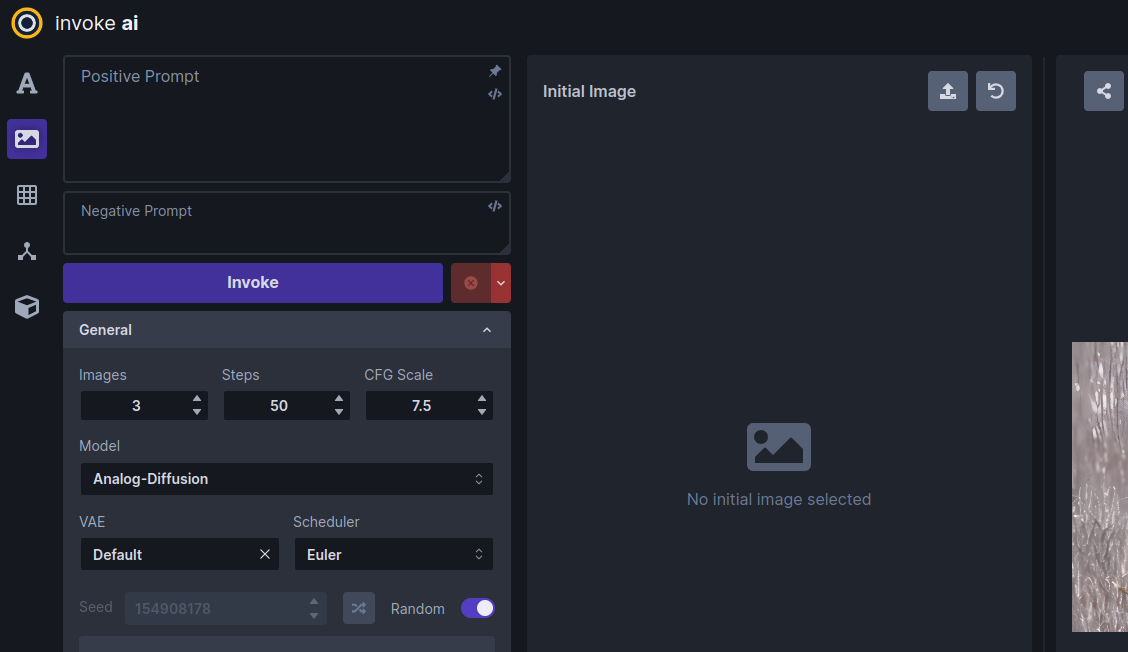
单击“图像到图像”选项卡图标,这是屏幕左侧从顶部开始的第二个图标。这将带您进入类似于此处所示的屏幕:
-
将林肯和鹦鹉图像拖放到图像面板中,或单击空白区域以打开上传对话框。图像将加载到标记为“初始图像”的区域中。 (WebUI 还会将图库中最近生成的图像加载到左侧的部分中,但该图像将在下一步中被替换。)
-
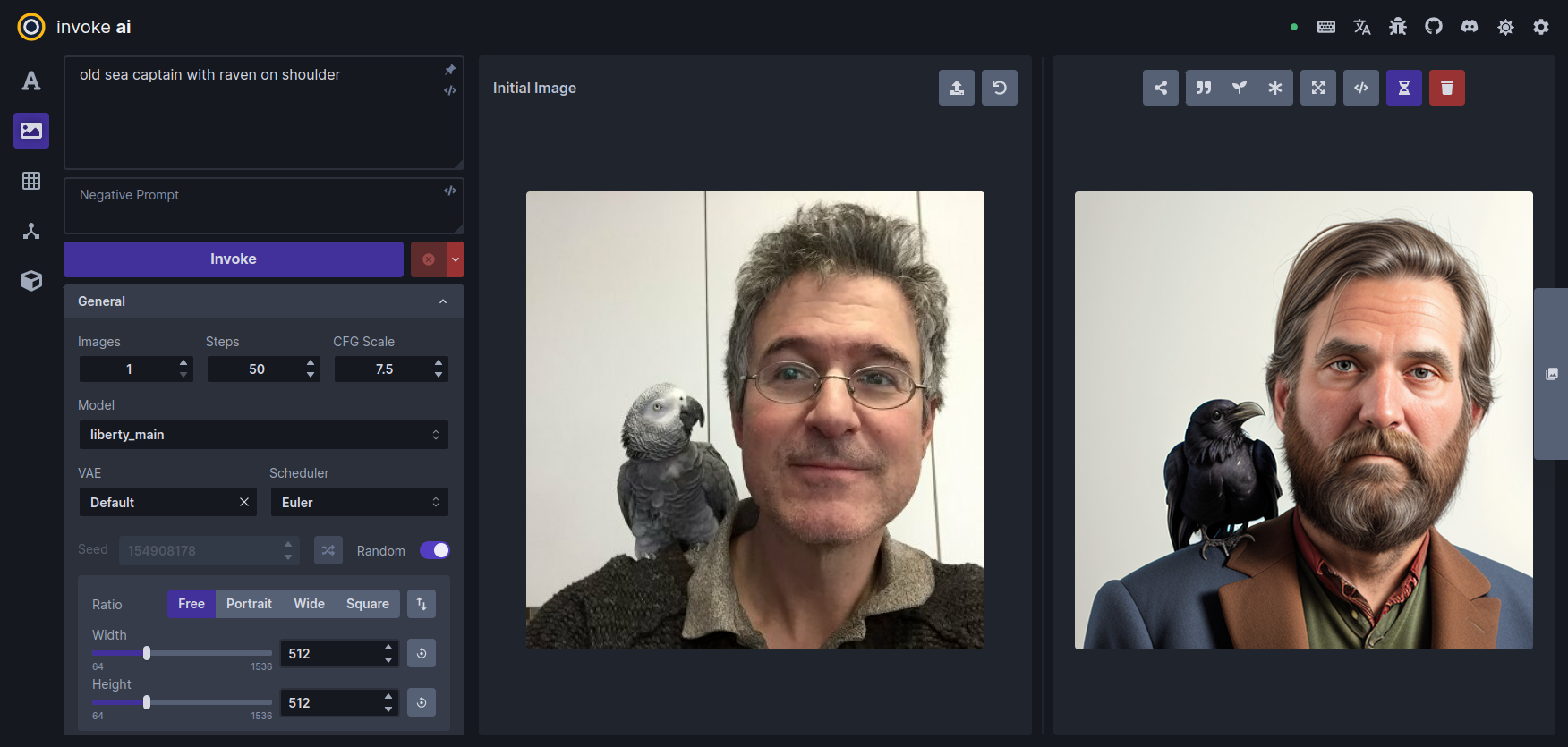
转到提示框并输入 old sea Captain with raven on Should 并按 Invoke。派生图像将出现在原始图像的右侧:
-
尝试不同的设置。 “图像到图像”中最有影响力的是“降噪强度”,位于控制面板的中间位置。默认情况下,它设置为 0.75,但范围可以从 0.0 到 0.99。值越高,AI 将替换的原始图像越多。值为 0 将使初始图像完全不变,而 0.99 将完全替换它。然而,Scheduler 和 CFG Scale 也会影响最终结果。您还可以按照文本到图像中所述的相同方式生成变体。
-
如果我们只想更改图像的某些部分而其余部分保持不变怎么办?这称为修复,您可以在统一画布中进行。统一画布还允许您扩展图像的边界并填充空白区域,这一过程称为外画。
-
您想使用“图像到图像”工具修改先前生成的图像吗?简单的!在“图像到图像”面板中,将图库中的任何图像拖放到“初始图像”区域中,即可使用。您可以对主图像显示执行相同的操作。单击“发送到”图标以获取命令菜单,然后选择“发送到图像到图像”。
文本反转、LoRA 和 ControlNet #
InvokeAI 支持多种不同类型的模型文件,通过添加艺术风格、特效或主题来扩展主模型的功能。通过混合和匹配文本反演、LoRA 和 ControlNet 模型,您可以实现许多有趣且美观的效果。
我们将使用名为“Ink Scenery”的 LoRA 模型给出一个示例。这个 LoRA 可以从 Civitai (civitai.com) 下载,专门用于绘制看起来像是用滴墨画成的风景。要安装此LoRA,我们首先下载它并将其放入 invokeai 根目录内的 autoimport/lora 文件夹中。重新启动 Web 服务器后,LoRA 现在就可以使用了。
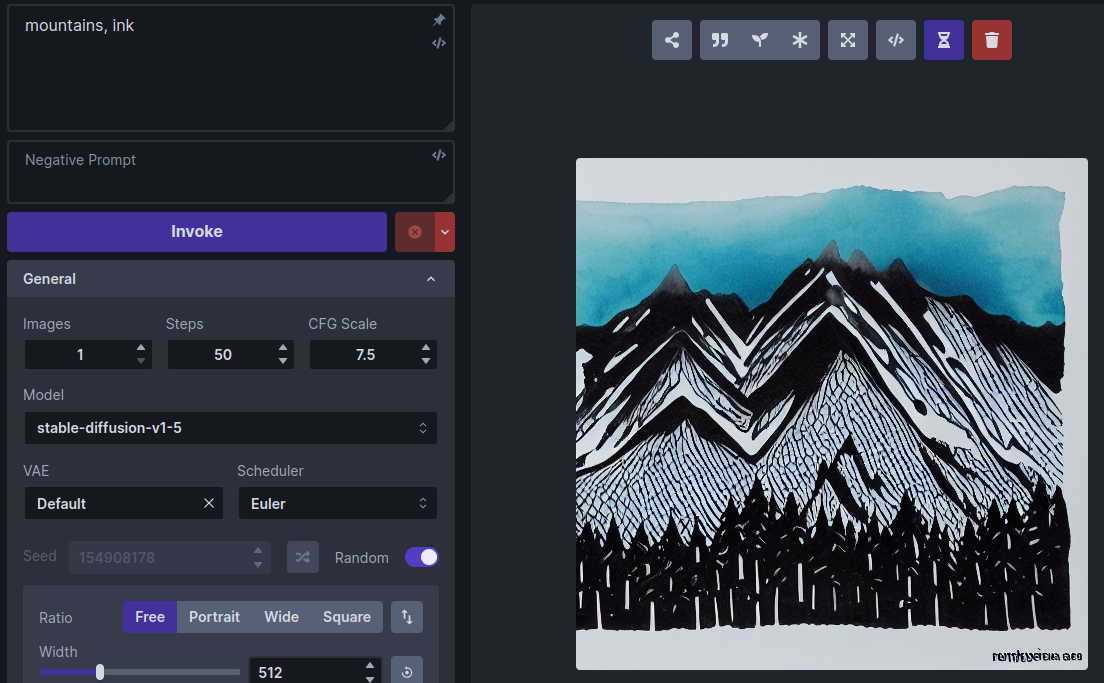
为了了解 LoRA 的工作原理,我们首先使用标准 stable-diffusion-v1-5 模型生成一个没有 LoRA 的图像。选择这个模型,输入提示“山,墨”。这是一个典型的生成图像,用墨水和水彩画渲染的山脉:
现在让我们安装并激活水墨风景LoRA。访问 https://civitai.com/models/78605/ink-scenery-or 并将 LoRA 模型文件下载到 invokeai/autoimport/lora 并重新启动 Web 服务器。 (或者,您可以使用 InvokeAI 的 Web Model Manager 通过在“导入模型”->“位置”字段中输入其 URL 来直接下载并安装 LoRA)。
向下滚动控制面板,直到到达 LoRA 手风琴部分,然后将其打开:
单击弹出菜单并选择“水墨风景”。 (如果不存在,则该模型未安装到正确的位置,或者您可能忘记重新启动 Web 服务器。)LoRA 部分将更改为如下所示:
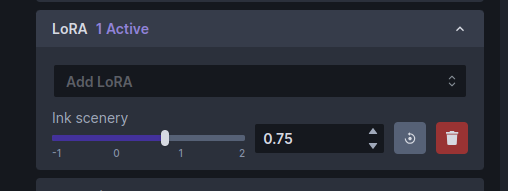
请注意,现在有一个用于墨水风景的滑块控件。滑块控制 LoRA 模型对生成图像的影响程度。
再次运行“山,墨”提示,观察样式的变化:
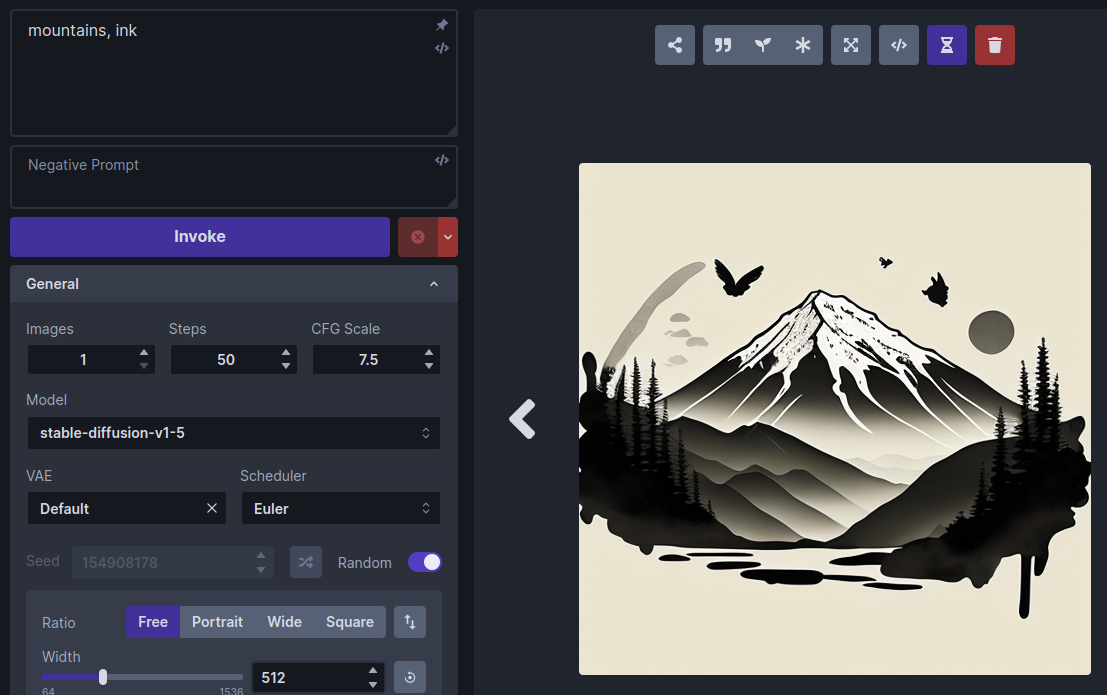
尝试调整权重滑块以获得更大和更小的权重,并在每次调整后生成图像。权重越高,LoRA 的影响力就越大。
要完全删除 LoRA,只需单击其垃圾桶图标即可。
可以同时添加多个 LoRA,并与文本反转和 ControlNet 模型相结合。有关详细信息,请参阅文本反转和 LoRA 以及使用 ControlNet。
评论(0)